
Read Time20 Minute, 3 Second
Amazon DynamoDB is a fully managed NoSQL database service designed to provide seamless scalability and high performance for modern applications. This primer explores all aspects of DynamoDB, from basic concepts to advanced features, complete with Python code examples to empower developers to integrate it effectively into their projects.
Contents
DynamoDB Basics
DynamoDB is a serverless, fully managed NoSQL database from AWS. It supports key-value and document database and ensures single-digit millisecond performance at any scale. It is fully serverless, automatically scaling to meet varying workloads without infrastructure management. Use cases include e-commerce platforms, IoT applications, mobile backends, and real-time analytics.
Before diving into implementation, it’s crucial to understand DynamoDB’s foundational concepts
Core Components
Tables
Tables in DynamoDB are collections of data, analogous to tables in a relational database. Each table requires a unique primary key.
Items
Individual records within a table, comprising one or more attributes. A table can have zero or more items. Each item is uniquely identifiable through primary keys.
Attributes
An attribute is a fundamental data element. A group of attributes form an item, represented as key-value pairs. It is analogous to columns in a relational database except that the schema is not fixed. Each item in a table can have varying attributes. Except the primary key attribute(s), no other attributes are expected to have values.
Primary Key
A primary key uniquely identifies an item within a table. Unlike relational databases where specifying a primary key for a table is optional, you must specify a primary key when creating a DynamoDB table.
There are two different kinds of primary keys in DynamoDB:
Partition Key
A partition key is a simple primary key composed of a single attribute.
Partition Key and Sort Key
A primary key composed of two keys: a partition key and a sort key. Also known as a composite key.
In both the cases, the partition key is hashed and its hash value determines the partition where the item is stored. If there is a sort key, it is used to determine the order in which the items are stored within a partition.
Secondary Indexes
Unlike relational databases, it is not easy and straightforward to query a DynamoDB table using any attribute. The GetItem API and the Query API support querying tables only using the primary key attributes. If you need to query a table using a non-primary key attribute, you must create Secondary indexes.
DynamoDB supports two kinds of secondary indexes:
Global Secondary Index (GSI)
GSI consists of a partition key and sort key that are different from those on the table. This helps you query a table on attributes that are not partition key and sort key on the table. GSI span the entire table.
Local Secondary Index (LSI)
LSI uses the same partition key as the table, but has a different sort key.
A DynamoDB table can have up to 20 GSI and 5 LSI. However, this Service quota is adjustable at the account level. For more information, check out Service, account, and table quotas in Amazon DynamoDB – Amazon DynamoDB
Data Types
DynamoDB supports the following data types:
Simple Types
Simple types represent a single value.
String
A Unicode type with UTF-8 binary encoding. Strings can be up to 400KB in size.
Number
A positive, negative or zero and supports up to 38 digits of precision.
Binary
Stores encrypted data, images, compressed text, etc. The maximum length of binary type is 400KB.
Boolean
Holds true or false value.
null
Represents an unknown or undefined state.
Complex Types
There are three complex types in DynamoDB:
List
A list is an ordered, heterogeneous collection of data separate by commas and enclosed within square brackets. It is analogous to JSON Arrays. The values can be of any data type, including other complex types like maps or lists. It’s analogous to Python’s List data type.
"Attributes": [
"Value1",
123,
{"S": "StringValue"},
[1, 2, 3]
]Map
A map is an unordered collection of name-value pairs that can be nested. It is analogous to JSON objects. Maps are enclosed within braces. Similar to lists, maps are heterogeneous too, which means that they can contain different types of data within them. It’s analogous to Python’s Dictionary data type.
"Attributes": {
"Attribute1": {"S": "StringValue"},
"Attribute2": {"N": "123"},
"SubAttributes": {
"SubKey1": {"S": "SubValue1"},
"SubKey2": {"N": "456"}
}
}Set
A set is a unordered, homogeneous collection of values containing the same type of data. The order of elements within a set is not preserved. A set must not be empty, however, the values within a set can be empty. Element names within a set must be unique. It’s analogous to Python’s Set data type.
DynamoDB supports three types of Sets:
- String Set (
SS): A set of unique strings. - Number Set (
NS): A set of unique numbers. - Binary Set (
BS): A set of unique binary values.
"Tags": {"SS": ["tag1", "tag2", "tag3"]},
"Scores": {"NS": [10, 20, 30]}| Aspect | List | Map | Set |
|---|---|---|---|
| Definition | An ordered collection of values. | An unordered collection of key-value pairs. | An unordered collection of unique values. |
| Data Type Support | Can contain any valid DynamoDB data type, including Lists, Maps, and scalar types. | Keys are strings, values can be any valid DynamoDB data type, including Lists and Maps. | String Set (SS), Number Set (NS), Binary Set (BS) |
| Ordered? | Yes | No | No |
| Allows Duplicates? | Yes | Keys: No Values: Yes | No |
| Use Case | When you need an ordered collection of items, e.g., list of tags, scores, etc. | When you need a collection of key-value pairs, e.g., user attributes or settings. | When you need a collection of unique items without duplicates, e.g., a list of unique user IDs or tags. |
| Structure | [value1, value2, value3, ...] | {key1: value1, key2: value2, ...} | {value1, value2, value3, ...} (set notation) |
| Example | {"L": [{"S": "apple"}, {"N": "10"}]} | {"M": {"name": {"S": "John"}, "age": {"N": "30"}}} | {"SS": ["tag1", "tag2"]} |
| Data Format | Stored as a list of elements. | Stored as a map of key-value pairs. | Stored as a set of unique elements. |
| Common Operations | Access elements by index. | Access elements by key. | Check for membership or uniqueness. |
For a list of all Python complex types, check out Python’s Core Sequence and Collection Types in 5 minutes – The Developer Space
Data Type descriptors
Data type descriptions are used by the DynamoDB API to tell DynamoDB how to interpret a value passed to APIs through parameters. The following is a complete list of DynamoDB data type descriptors:
| Descriptor | Data Type |
|---|---|
| S | String |
| N | Number |
| B | Binary |
| BOOL | Boolean |
| NULL | Null |
| M | Map |
| L | List |
| SS | String Set |
| NS | Number Set |
| BS | Binary Set |
Capacity Modes
Amazon DynamoDB offers two primary capacity modes to manage throughput for reading and writing data. These modes provide flexibility in balancing cost and performance based on the application’s workload.
On-Demand
Pay per request, ideal for unpredictable workloads. DynamoDB automatically scales capacity to handle incoming requests. You pay only for the read and write operations performed.
Provisioned
In this mode, you specify the amount of read and write capacity your application requires. DynamoDB reserves the specified capacity to ensure consistent performance. This mode is suited for predictable high volume workloads.
Storage Class
In DynamoDB, storage class defines how data is stored and managed to optimize costs and performance. They allow developers to choose the most cost-efficient storage option for their application’s needs while maintaining performance for frequently accessed data and reducing costs for infrequently accessed data.
DynamoDB provides two storage classes:
Standard Storage Class (Default)
This is the default and most commonly used storage class, that is optimized for tables with regular and high data access requirements
Standard-IA (Infrequent Access) Storage Class
This class is designed for storing infrequently accessed data at a lower cost. Storage costs are lower than the Standard Storage Class, but read and write costs are higher. This is suitable for archival data, historical records, or logs that are rarely accessed but must remain available.
DynamoDB Streams
Amazon DynamoDB Streams is a feature that captures a time-ordered sequence of changes (modifications) made to items in a DynamoDB table. This stream can be used to build event-driven applications, perform real-time analytics, replicate data across regions, or trigger downstream processes.
Global Tables
Global Tables allows you to replicate your DynamoDB tables across multiple AWS regions. This replication ensures low-latency access to data for globally distributed applications while providing high availability and disaster recovery.
Global Tables automatically synchronize changes made to the data across all replica tables, offering a fully managed multi-region replication solution with 99.999% availability.
Transactions
Transactions enable ACID-compliant operations (Atomicity, Consistency, Isolation, Durability) on one or more items across multiple tables. This ensures data integrity for complex workflows, such as order processing or financial applications, where multiple interdependent actions must succeed or fail as a single unit. DynamoDB provides support for ACID-compliant transactions.
Time-to-live (TTL)
DynamoDB supports TTL that automatically deletes items when they expire. This feature helps you to automatically remove temporary and transient data and maintain the database size while saving on storage costs. For more information, check out Using time to live (TTL) in DynamoDB – Amazon DynamoDB
Working with DynamoDB
Prerequisites
AWS Account
DynamoDB is a Database as a Service platform that is available in the AWS environment. To start exploring DynamoDB, sign up at AWS.
Access methods
DynamoDB can be access through three ways:
AWS Management Console
Once you’ve set up your AWS account, go to DynamoDB console. You will be able to view the list of tables, explore items within each table and also run queries against the tables.
AWS Command Line Interface (CLI)
CLI allows you to interact with DynamoDB using command line scripts and is specifically useful for automating your DynamoDB initial setup. Follow the instructions for Installing the AWS CLI and Configuring the AWS CLI.
DynamoDB API
The DynamoDB API is a set of programmatic interfaces provided by Amazon DynamoDB to enable developers to interact with DynamoDB tables programmatically. These APIs offer low-level access to perform operations like creating tables, reading and writing data, updating attributes, querying and scanning data, and managing database settings.
The API supports multiple programming languages through AWS SDKs, making it versatile and suitable for a wide variety of applications. This article shows you how to perform DynamoDB operations using the boto3 library and the Python programming language. However, you can also try these out with any other supported programming language by using the appropriate SDK. For more information on using Python and boto3 to access DynamoDB, check out Programming Amazon DynamoDB with Python and Boto3 – Amazon DynamoDB
PartiQL
PartiQL (pronounced “particle”) is a structured query language developed by AWS for querying, inserting, updating, and deleting data across different data formats, including relational, non-relational, and semi-structured datasets. It is supported in Amazon DynamoDB to provide a SQL-compatible interface for interacting with the database.
Basic Operations
Creating a Table
Let’s create a Products table with ProductID as the partition key and Year as the sort key.
import boto3
dynamodb = boto3.resource('dynamodb')
# Create the table
table = dynamodb.create_table(
TableName='Products',
KeySchema=[
{'AttributeName': 'ProductID', 'KeyType': 'HASH'}, # Partition key
{'AttributeName': 'Year', 'KeyType': 'RANGE'} # Sort key
],
AttributeDefinitions=[
{'AttributeName': 'ProductID', 'AttributeType': 'S'},
{'AttributeName': 'Year', 'AttributeType': 'N'}
],
ProvisionedThroughput={
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
)
# Wait for the table to be created
table.meta.client.get_waiter('table_exists').wait(TableName='Products')
print(f"Table {table.table_name} created successfully!")Inserting Data
Add records with attributes like ProductName, Category, and CustomerRating.
products_table = dynamodb.Table('Products')
# Add items
products_table.put_item(
Item={
'ProductID': 'P001',
'Year': 2021,
'ProductName': 'Air Fryer',
'Category': 'Appliances',
'CustomerRating': 4
}
)
products_table.put_item(
Item={
'ProductID': 'P002',
'Year': 2020,
'ProductName': 'Samsung Tablet',
'Category': 'Electronics',
'CustomerRating': 4.5
}
)
print("Products added successfully!")After you’ve created the data and inserted items, you can verify them from the AWS console.
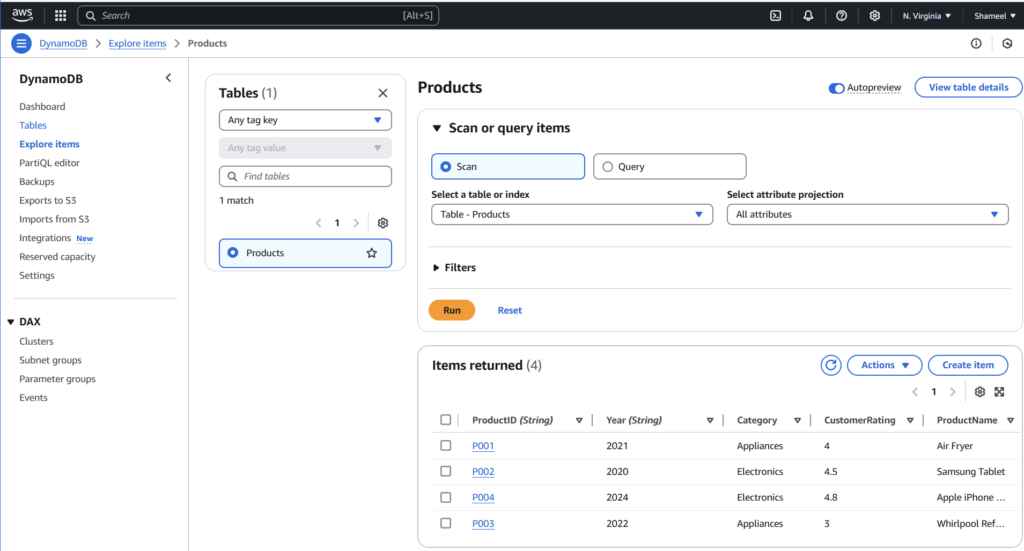
Working with Data
Fetch a Single Item
Use the get_item method to fetch a single item a from a table using its partition key and sort key (optional).
response = products_table.get_item(Key={'ProductID': 'P001', 'Year': 2021})
print("Product Details:", response['Item'])Query Items
Use the query method to query a table using its partition key and sort key (optional). It returns all items matching the query criteria.
from boto3.dynamodb.conditions import Key
response = products_table.query(
KeyConditionExpression=Key('ProductID').eq('P001') & Key('Year').eq(2021)
)
print("Queried Products:", response['Items'])Scan All Items
The scan method scans the entire table or index.
response = products_table.scan()
print("All Products:", response['Items'])Delete an Item
The delete_item method scans the entire table or index.
table = dynamodb.Table('Products')
key = {
'ProductID': 'P004', # Partition key
'Year': 2024 # Sort key
}
response = table.delete_item(
Key=key
)
if response['ResponseMetadata']['HTTPStatusCode'] == 200:
print("Item deleted successfully!")
else:
print("Failed to delete the item.")Working with multiple items
DynamoDB provides batch operations for handling multiple items at once.
BatchGetItem
Retrieve multiple items in a single request.
response = dynamodb.batch_get_item(
RequestItems={
'Products': {
'Keys': [
{'ProductID': {'S': 'P001'}},
{'ProductID': {'S': 'P002'}},
# Add more keys here
]
}
}
)
print(response['Responses']['Products'])BatchWriteItem
Write multiple items (put or delete) in a single request. You can mix PutRequest and DeleteRequest in the same batch operation. However, you can only have a maximum of 25 items per batch. A batch can have a maximum data size of 16 MB. Operations in a batch are not atomic. Some operations might succeed while others might fail. Failed operations (e.g., due to throttling or other issues) are returned in the UnprocessedItems field of the response.
response = dynamodb.batch_write_item(
RequestItems={
'Products': [
{'PutRequest': {'Item': {'ProductID': {'S': 'P005'}, 'Year': {'N': '1974'}, 'ProductName': {'S': 'Rubik Cube'}, 'Category': {'S': 'Toys'}, 'CustomerRating': {'N': '5'}}}},
{'PutRequest': {'Item': {'ProductID': {'S': 'P006'}, 'Year': {'N': '1945'}, 'ProductName': {'S': 'Animal Farm'}, 'Category': {'S': 'Books'}, 'CustomerRating': {'N': '5'}}}}
]
}
)
# Check for unprocessed items
unprocessed_items = response.get('UnprocessedItems', {})
if unprocessed_items:
print(f"Some items were not processed: {unprocessed_items}")
else:
print("All items inserted successfully!")Handling Errors
DynamoDB may return some items in the UnprocessedItems field due to throttling or exceeding resource limits. You must retry these operations manually. For larger operations, split items into chunks of 25 using libraries like itertools or custom logic.
Deleting a Table
Use the delete method to delete an entire table.
table.delete()
table.meta.client.get_waiter('table_not_exists').wait(TableName='Products')
print("Table deleted successfully!")Secondary Indexes
DynamoDB provides support for Secondary indexes to enable you to query tables using non pimary key attributes.
Create a GSI
The table.update method is used to create secondary indexes on table. The GlobalSecondaryIndexUpdates attribute provides the index specifications.
table.update(
AttributeDefinitions=[
{'AttributeName': 'Category', 'AttributeType': 'S'}
],
GlobalSecondaryIndexUpdates=[
{
'Create': {
'IndexName': 'CategoryIndex',
'KeySchema': [
{'AttributeName': 'Category', 'KeyType': 'HASH'}
],
'Projection': {'ProjectionType': 'ALL'},
'ProvisionedThroughput': {
'ReadCapacityUnits': 5,
'WriteCapacityUnits': 5
}
}
}
]
)Query a table using GSI
The IndexName attribute of the query method is used to specify the index to be used to query the table.
response = table.query(
IndexName='CategoryIndex',
KeyConditionExpression=Key('Category').eq('Electronics')
)
print("Products in Electronics Category:", response['Items'])DynamoDB Streams
This example shows how to enable Streams on a DynamoDB table.
table.update(StreamSpecification={
'StreamEnabled': True,
'StreamViewType': 'NEW_AND_OLD_IMAGES'
})
print("Streams enabled!")Transactions
This examples shows how you can insert a product and delete a product within a transaction. In this case, both Put and Delete operations either succeed or fail together as one unit.
dynamodb_client = boto3.client('dynamodb')
response = dynamodb_client.transact_write_items(
TransactItems=[
{
'Put': {
'TableName': 'Products',
'Item': {
'ProductID': {'S': 'P003'},
'Year': {'N': '2022'},
'ProductName': {'S': 'Whirlpool Refrigerator'},
'Category': {'S': 'Appliances'},
'CustomerRating': {'N': '3'}
}
}
},
{
'Delete': {
'TableName': 'Products',
'Key': {
'ProductID': {'S': 'P002'},
'Year': {'N': '2020'}
}
}
}
]
)
print("Transaction completed successfully!")For a list of all API operations, check out Amazon DynamoDB – Amazon DynamoDB
Monitoring and Debugging
Monitoring and debugging are crucial aspects of working with DynamoDB to ensure optimal performance, troubleshoot issues, and maintain system health. AWS provides several tools and features to monitor the performance of DynamoDB tables and track operations for debugging purposes.
CloudWatch Metrics
CloudWatch provides a wide range of performance metrics for DynamoDB. These metrics help you understand how well your tables are performing and alert you to potential issues.
Some important CloudWatch metrics for DynamoDB include:
- ConsumedReadCapacityUnits: Tracks the number of read capacity units consumed.
- ConsumedWriteCapacityUnits: Tracks the number of write capacity units consumed.
- ReadThrottleEvents: The number of read requests that exceeded the provisioned throughput.
- WriteThrottleEvents: The number of write requests that exceeded the provisioned throughput.
- SystemErrors: The number of internal server errors.
- ThrottledRequests: The number of requests that were throttled due to exceeding provisioned throughput.
- Latency Metrics: Measures the time taken for DynamoDB operations, such as
GetItem,PutItem, andQuery.
CloudWatch Alarms
You can set CloudWatch alarms on these metrics to receive notifications when they cross specific thresholds. For example:
- An alarm for ReadThrottleEvents or WriteThrottleEvents can alert you if your table is being throttled, indicating that the provisioned throughput might need adjustment.
- An alarm on SystemErrors can notify you of internal server issues.
AWS CloudTrail
CloudTrail provides logs of all AWS API calls, including those made to DynamoDB. CloudTrail helps you trace the source of any operation, such as PutItem, Query, or UpdateItem, by showing the request parameters, including the IP address, time, and requestor’s identity.
Using CloudTrail, you can:
- Investigate unauthorized access or operational issues.
- Identify the cause of unexpected changes or deletions in your DynamoDB table.
- Monitor for any malicious or unintended API activity.
DynamoDB vs Other Databases
| Feature | DynamoDB | Relational Databases (e.g., RDS) | MongoDB |
|---|---|---|---|
| Schema | Schema-less | Schema-defined | Schema-less |
| Scalability | Automatic | Manual | Automatic |
| Query Language | API-based/PartiQL | SQL | API-based |
| Transactions | Supported | Supported | Supported |
| Use Cases | IoT, gaming, etc. | ERP, CRM, etc. | CMS, real-time data |
References
What is Amazon DynamoDB? – Amazon DynamoDB
Supported data types and naming rules in Amazon DynamoDB – Amazon DynamoDB
Programming Amazon DynamoDB with Python and Boto3 – Amazon DynamoDB
PartiQL – a SQL-compatible query language for Amazon DynamoDB – Amazon DynamoDB
Programmatic interfaces that work with DynamoDB – Amazon DynamoDB
Using time to live (TTL) in DynamoDB – Amazon DynamoDB
Global tables – multi-Region replication for DynamoDB – Amazon DynamoDB
Amazon DynamoDB Transactions: How it works – Amazon DynamoDB
Improving data access with secondary indexes in DynamoDB – Amazon DynamoDB
Service, account, and table quotas in Amazon DynamoDB – Amazon DynamoDB
Summary
This article covered DynamoDB’s core concepts, including tables, keys, indexes, and capacity modes, along with advanced features like DynamoDB Streams, Global Tables, and ACID transactions. Through practical Python code examples, we saw how to create, query, and manage DynamoDB tables efficiently. Additionally, it also explored integration with AWS services, monitoring with CloudWatch, cost optimization strategies, and best practices for designing scalable and resilient applications. Whether you’re new to DynamoDB or looking to deepen your knowledge, this article provides a solid coverage of all aspects of DynamoDB that developers need to be aware of. By mastering these features and principles, developers can harness DynamoDB’s capabilities to build scalable, resilient applications while managing costs and optimizing performance.


[…] Polyglot Persistence: A Comprehensive Guide for Database Developers Transitioning to Microservices Architecture Amazon DynamoDB: A Developer’s Comprehensive Primer […]