Read Time16 Minute, 19 Second
Generative AI is transforming how we create text, images, code, and other forms of digital content. Amazon Web Services (AWS) has emerged as a significant player in the generative AI space with services and tools that enable developers and businesses to build, train, and deploy AI models with ease.
This article is a continuation of the first article in the series:
Comparison of Generative AI Solutions: AWS vs Azure vs Google Cloud (2024 Guide).
If you have not read the previous article, I strongly recommend that you read it before continuing with this article.
Contents
Generative AI on AWS
Amazon Web Services (AWS) has played a pivotal role in the evolution of Generative AI, continuously expanding its services to support the growing demands of AI-driven innovation. AWS provides different services, tools and models to implement and use Generative AI on its platform. Most use cases around Generative AI involve end-user experiences. AWS makes it easy to build, deploy and scale Generative AI applications and services with security and privacy built-in.
There are three main components for implementing generative AI applications in AWS:
- Amazon Bedrock provides a unified platform for accessing the features provided by different models in a seamless manner.
- Foundation Models are core elements in machine learning that learn from data to make predictions or automate decision-making processes.
- Amazon SageMaker provides a platform to host, train and fine-tune models to improve their speed and accuracy and to adapt them to the required use cases.
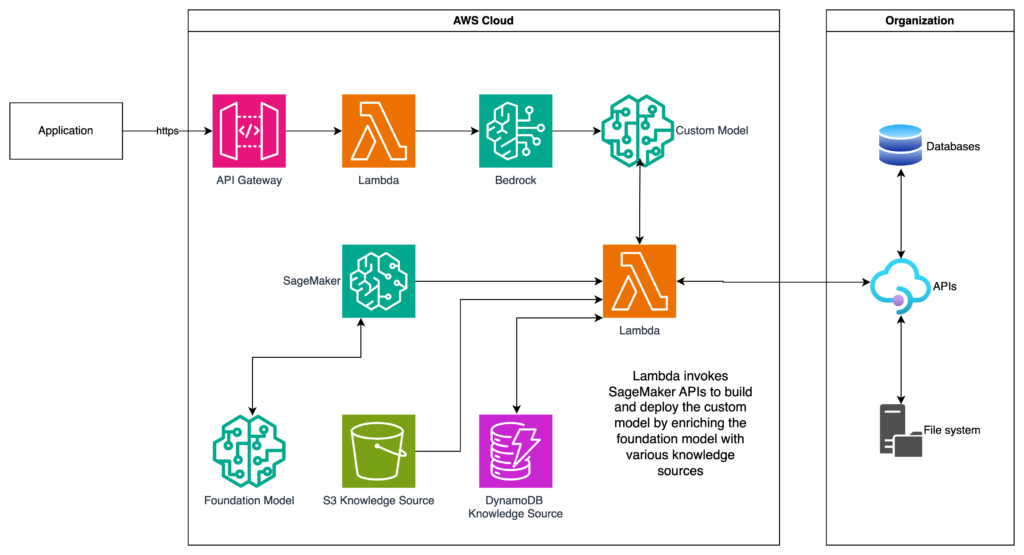
Reference Architecture
Here’s a high-level reference archiecture of how a typical generative AI application in AWS may look like:
Amazon Bedrock
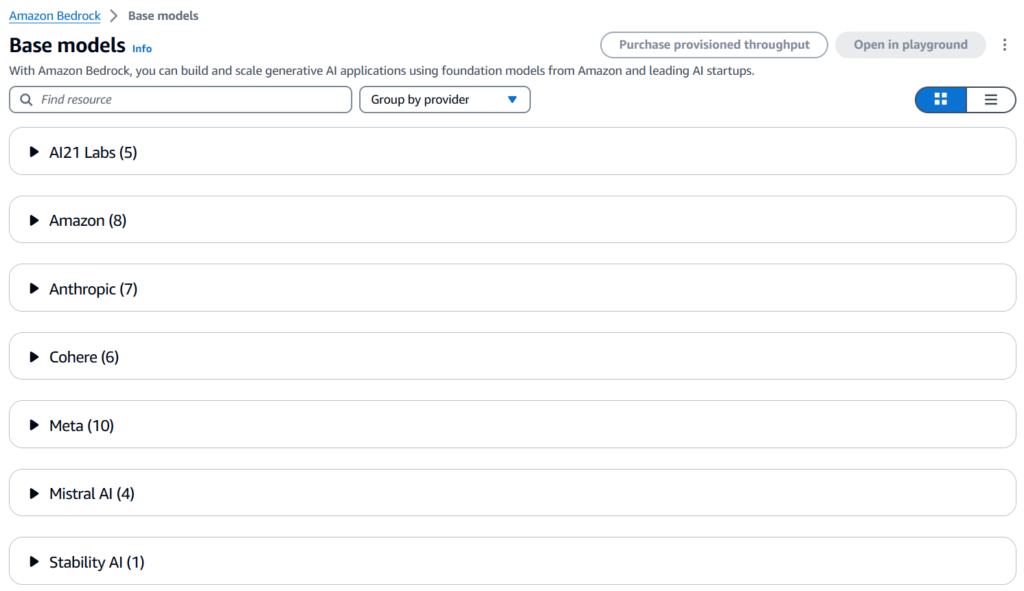
Amazon Bedrock, introduced in 2023, is a fully managed service that provides a unified platform to access multiple Foundation Models (FMs) from several leading AI companies like AI21 Labs, Anthropic, Stability AI, and also Amazon’s own proprietary models like Titan. This flexibility allows users to choose from different models depending on their specific needs. It offers an ecosystem to build generative AI applications and services with security, privacy and responsible AI practices.
Knowledge Bases
Knowledge Bases allow Foundation Models and Bedrock Agents to access contextual information from the organization’s private data sources to implement RAG. It enables Bedrock to provide accurate, relevant and customized responses.
Agents
Bedrock Agent is a service within Amazon Bedrock designed to facilitate the development of generative AI-powered applications by integrating foundation models with external data sources and APIs. Agents allow developers to enhance the capabilities of pre-trained foundation models, such as LLMs (Large Language Models), by enabling them to perform specific tasks using real-time data, applications, and custom logic.
Guardrails
Bedrock Guardrails are built-in safety mechanisms within Amazon Bedrock that ensure the responsible use of generative AI models by preventing them from generating harmful, inappropriate, or unintended content. These guardrails help developers manage the risks associated with deploying large-scale foundation models (like LLMs and Generative AI models) by enforcing ethical guidelines, security policies, and content quality checks.
Guardrails are especially useful in use cases where the responses from generative AI models are shared with end users directly and must be checked for profanity, inappropriateness, offensive contents, etc.
Bedrock Studio
Amazon Bedrock Studio is a web interface designed to help developers experiment with and build generative AI applications. It provides a rapid prototyping environment and streamlines access to multiple foundation models (FMs) and developer tools.
Amazon Bedrock Studio allows developers to collaborate on projects within their organization, experiment with different LLMs and Foundation Models without needing to set up a developer environment, create prototype apps using Amazon Bedrock models and features such as Knowledge Bases or Guardrails, without writing any code. It’s designed to make it easy for developers to get started with generative AI applications quickly and efficiently.
Amazon Bedrock Features
Model Variety
Provides access to multiple Foundation Models (FMs) from different providers, giving users flexibility based on their use cases. AWS also provides a model evaluation tool to evaluate accuracy of models for specific use cases.
Integration with AWS Services
Bedrock integrates seamlessly with AWS services like Lambda and SageMaker, allowing users to build, deploy, manage and access AI models quickly and efficiently.
Model Customization
Bedrock allows you to customize and fine-tune models with domain information to improve the accuracy of models for specific use cases.
Retrieval Augmented Generation (RAG)
RAG is an AI technique that enables you to augment and enrich responses generated by Foundation Models with custom data from Knowledge Bases, documents, databases and other backend systems. This process helps you to enhance the accuracy and relevance of generated content.
Foundation Models
Foundation Models are general-purpose language models that are more versatile and require less data. The foundation models can be customized and fine-tuned for specific use cases. Unlike Large Language Models (LLMs), they’re not specialized and do not need large data. AWS provides different foundation models for you to choose from. Each of these models are suited for multiple use cases.
Titan
Amazon Titan are a family of models built by AWS that are pre-trained on large datasets, which makes them powerful, general-purpose models. The Titan models are optimized for tasks such as summarization, text generation, search queries, and chatbot applications. These models are integrated into various AWS services, enabling seamless deployment across the AWS ecosystem.
Claude
Claude by Anthropic is designed with a focus on safety, providing outputs that are less likely to generate harmful or unsafe content. This makes it ideal for businesses requiring a higher standard of compliance and responsibility. This model is also highly suitable for building customer facing conversational interfaces. It has a 200,000 token context window which allows you to relay large amount of data to the model. (A token roughly equals 0.75 words)
Jurassic-2
Jurassic-2 by AI21 Labs is a versatile LLM with strong capabilities in text generation, content creation, summarization, and translation. It is designed to handle multi-language support with extensive control over outputs. Jurassic-2 models are known for their high-performance capabilities and fine-grained control over generated outputs. One of its key features is its ability to generate long-form, coherent text, making it suitable for applications in content creation, virtual assistants, and customer support. Jurassic-2 emphasizes on user control, providing parameters that allow developers to adjust and fine-tune the tone, style, and precision of the generated content. This makes it more versatile for specific use cases like creative writing, technical documentation, or conversational AI.
Jamba
The Jamba 1.5 Model Family by AI21 Labs contains many models like Large, Mid, Mini and Instruct. Some models have a 256K token effective context window, one of the largest on the market. Jamba 1.5 models focus on speed and efficiency, delivering up to 2.5x faster inference than leading models of comparable size. Jamba 1.5 models support multiple languages, but do not support fine-tuning.
Llama
LLaMA (Large Language Model Meta AI) is a family of large language models developed by Meta (formerly Facebook) that excels in natural language understanding and generation. LLaMA is designed to be efficient, using fewer parameters compared to some of its peers, while still maintaining high performance in various NLP tasks like text completion, translation, and summarization. With a focus on research and academic use, LLaMA is optimized for use in environments where computational resources might be limited, yet high-quality results are needed. Its lightweight architecture makes it accessible for developers to fine-tune and deploy in specialized applications, and it’s recognized for advancing open-access research in AI language models.
Llama 2 is a high-performance, auto-regressive language model designed for developers. It uses an optimized transformer architecture and pre-trained models are trained on 2 trillion tokens with a 4k context length. Llama 3 is an accessible, open model designed for developers, researchers, and businesses to build, experiment, and responsibly scale their generative AI ideas.
Stable Diffusion
Stable Diffusion by Stability AI is a cutting-edge generative AI model designed to create high-quality images from text descriptions. Developed by Stability AI, this model uses advanced diffusion processes to generate detailed and realistic images, making it one of the most powerful tools in the domain of AI-driven image creation. It is particularly useful for tasks like graphic design, product visualization, and creative content generation.
Cohere
Cohere‘s Command and Embed models are particularly suited for tasks like semantic search, text classification, and language translation, offering high-quality natural language processing capabilities. With Cohere, developers can leverage embeddings to represent textual data in vector form, facilitating tasks such as recommendation systems or document clustering.
Mistral
Mistral AI is an advanced model known for its efficiency and flexibility in natural language understanding and generation tasks. Designed for high-performance applications, Mistral excels at tasks such as content creation, question-answering, summarization, and conversational AI. Current models offered by Mistral do not support fine-tuning.
Amazon SageMaker
Amazon SageMaker is AWS’s comprehensive machine learning platform, offering capabilities for building, training, and deploying custom LLMs. SageMaker provides full flexibility to deploy pre-built models or fine-tune them with your own data. SageMaker supports custom models trained using frameworks like PyTorch, TensorFlow, and Hugging Face, which can also integrate with LLMs from other sources. There are two primary ways to build a model in SageMaker: Canvas and Studio.
SageMaker Canvas
SageMaker Canvas is designed for business analysts and non-technical users who want to build machine learning models without needing to write code. Canvas provides a no-code, drag-and-drop interface, making it easy for users with limited ML knowledge to generate predictions and insights.
SageMaker Studio
SageMaker Studio provides a comprehensive set of purpose-built tools to support every stage of machine learning (ML) development. From data preparation to model building, training, deployment, and management, SageMaker Studio offers everything you need in one place. You can easily upload data and create models using your preferred integrated development environment (IDE). It also enhances collaboration within ML teams, allows for efficient coding with an AI-powered assistant, simplifies model tuning and debugging, and supports seamless deployment and management of models in production. Plus, you can automate workflows—all through a single, unified web interface. This is geared towards data scientists, ML engineers, and developers who require a more advanced, integrated development environment (IDE) for building, training, and deploying machine learning models. Studio provides a full set of tools for every step of the ML lifecycle, including model development, experimentation, debugging, and deployment.
While both Canvas and Studio enable you to build ML models, there are a few key differences:
| Feature | SageMaker Canvas | SageMaker Studio |
|---|---|---|
| Target Audience | Business Analysts, Non-technical Users | Data Scientists, ML Engineers, Developers |
| Code Requirement | No-code | Code-first |
| Use Case | Quick predictions, Business insights | Advanced ML workflows, Custom models |
| Ease of Use | Very easy, drag-and-drop interface | Requires coding and ML expertise |
| Customization | Limited customization, automated models | Full control, customizable workflows |
| Integration | Accesses pre-trained models from Studio | Fully integrated with SageMaker services |
| Collaboration | Collaborate with data scientists | Full collaboration within ML teams |
SageMaker Pipelines
SageMaker Pipeline is a sequence of connected steps organized in a directed acyclic graph (DAG), which can be created using a drag-and-drop interface or the Pipelines SDK. You can also define your pipeline using a JSON schema, called the pipeline definition JSON schema. This JSON format outlines the requirements and relationships between each step in the pipeline. The structure of the DAG is shaped by data dependencies between steps—where the output of one step is used as the input for another.
SageMaker JumpStart
SageMaker JumpStart is a ML hub that allows users to quickly deploy and fine-tune pre-built LLMs for tasks like text generation, sentiment analysis, and more.
Amazon SageMaker Features
Integration with Bedrock
Enables the fine-tuning of large language models available via Bedrock.
Customization and Fine-Tuning
Amazon SageMaker can be used in conjunction with Bedrock for training and fine-tuning models based on proprietary data.
Model Evaluation and Selection
Amazon Bedrock allows you to evaluate, compare and select the best Foundation Model for your use case. Amazon Bedrock offers a choice of automatic evaluation and human evaluation.
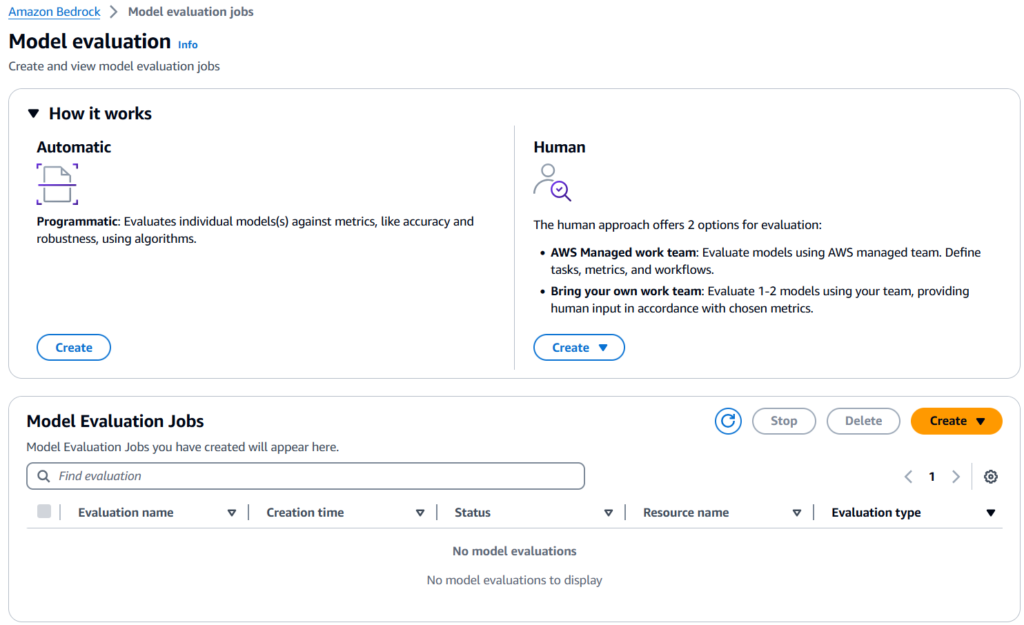
Automatic Evaluation
You can use automatic evaluation with predefined metrics such as accuracy, robustness, and toxicity.
Human Evaluation
For subjective or custom metrics, such as friendliness, style, and alignment to brand voice, you can set up human evaluation workflows with just a few clicks.
For more information, check out this blog post.
What’s in for Developers?
For developers, Generative AI on AWS offers a wide range of tools, services, and resources that make it easier to build, deploy, and scale AI-powered applications. Here’s what’s in store for developers leveraging AWS for generative AI:
- API access to the Bedrock platform using boto3 framework to access the different Foundation Models through a unified approach that improves developer experience and speeds up application development.
- API access to the SageMaker platform using boto3 framework to train and fine-tune models.
- Easy integration with AWS services like Lambda, S3, API Gateway and hosting solutions like Fargate, ECS and EC2.
More on this in a separate article later.
Use Case Matrix
This table contains the recommended models to be used for specific use cases. You can evaluate multiple models for your specific use case and determine the right model to use, using the Model evaluation option in Bedrock.
| Use Case | Description | Models |
|---|---|---|
| Text Generation | Generate coherent text, articles, or stories. | Jurassic-2, Amazon Titan |
| Text Summarization | Condense long articles, documents, or reports into shorter summaries. | Jurassic-2, Amazon Titan |
| Content Creation | Generate blog posts, marketing copy, or social media content. | Jurassic-2, Amazon Titan |
| Translation | Translate text between languages. | Jurassic-2, Amazon Titan |
| Document Summarization | Summarize long-form documents, such as research papers. | Claude, Amazon Titan |
| Creative Writing | Generate stories, poetry, or other forms of creative literature. | Jurassic-2, Amazon Titan |
| Chatbots & Conversational AI | Build virtual assistants for customer support or general inquiries. | Claude, Amazon Titan |
| Sentiment Analysis | Analyze the sentiment (positive, neutral, or negative) of a given text. | BERT, T5, RoBERTa |
| Code Generation | Write, complete and explain programming code based on user input. | Amazon SageMaker |
| Code Debugging | Assist developers in finding and fixing bugs in code. | Amazon SageMaker |
| Question Answering | Provide concise answers to questions from a knowledge base or document. | Jurassic-2, Amazon Titan |
| Educational Tutoring | Provide educational assistance or tutoring on various subjects. | - |
| Text-to-Image Generation | Create images from textual descriptions (e.g., "A cat wearing a space helmet"). | Stable Diffusion |
| Image Generation | Create realistic images from text. | Stable Diffusion |
| Personalized Recommendations | Generate personalized recommendations for products, content, etc. | Amazon Titan |
| Speech-to-Text & Voice Bots | Transcribe spoken language to text or powering voice-based assistants. | Amazon Polly |
| Product Design | Assist in the design and prototyping of products via image generation. | Stable Diffusion |
| Enterprise Search | Enhance internal search engines to provide intelligent, context-aware results. | Claude, Amazon Titan |
| Legal Document Analysis | Analyze and summarize complex legal documents or contracts. | Claude, Jurassic-2, Amazon Titan |
| Regulatory Compliance | Analyze documents for compliance with legal and industry regulations. | Claude, Amazon Titan, BERT |
Best Practices
There are several best practices when deploying generative AI models on AWS to ensure efficiency, scalability, and cost-effectiveness:
1. Choose the Right Instance Type
For training large models, AWS offers GPU-based instances like the P3 or G5 instances, which provide significant acceleration for training deep learning models. For inference, you can opt for less expensive CPU-based instances like M5 or Inf1.
2. Use SageMaker Pipelines
SageMaker Pipelines allows you to automate end-to-end ML workflows. This is particularly useful when working with complex generative AI workflows that require frequent retraining and model updates.
3. Leverage Spot Instances
For non-critical workloads, using Spot instances can reduce training costs significantly. Spot instances allow you to use AWS’s unused EC2 capacity at a fraction of the cost.
4. Optimize Model Inference with Elastic Inference
Elastic Inference allows you to attach just the right amount of inference acceleration to any EC2 or SageMaker instance, reducing costs for serving generative models at scale.
5. Monitor and Fine-tune Your Models
Once your models are in production, it’s crucial to monitor performance and fine-tune them regularly to keep them up to date with changes in user behavior or data patterns.
Conclusion
Generative AI on AWS is rapidly changing the landscape of artificial intelligence by making powerful models more accessible. With Bedrock and SageMaker, businesses can build, customize, and deploy generative models with ease, whether they’re working with text, images, or other content types. By leveraging foundation models and following best practices, AWS enables the creation of intelligent and scalable AI applications for a wide range of industries.


[…] I recommend that you read my previous article that gives an overview of Generative AI on AWS. Generative AI on AWS: 2025 Guide to Bedrock, Foundation Models and SageMaker. To understand Generative AI platforms offered by different cloud providers, head on to Comparison […]