Read Time13 Minute, 30 Second
Contents
Introduction
Polyglot persistence is the practice of using different types of databases to store different types of data within a single application. This approach recognizes that no single database technology is optimal for all types of data and use cases. Instead, it advocates for the use of multiple databases, each chosen for its strengths in handling specific data requirements.
In the evolving landscape of software architecture, the shift from monolithic designs to microservices has become a dominant trend. This transition is driven by the need for greater scalability, flexibility, and resilience in modern applications. However, this shift also introduces new challenges, particularly in the realm of data persistence. One of the key concepts that has emerged to address these challenges is polyglot persistence. For database developers moving from a monolithic architecture to a microservices architecture, understanding polyglot persistence is crucial. This article explores the concept in depth, discussing its benefits, challenges, and best practices, and provides guidance on how to implement it effectively in a microservices environment.
The Evolution from Monolithic to Microservices Architecture
Monolithic Architecture
In a monolithic architecture, an application is built as a single, unified unit. All components of the application, including the user interface, business logic, and data access layer, are tightly coupled and typically run in a single process. This approach has several advantages, including simplicity of development, deployment, and testing.
However, as applications grow in size and complexity, monolithic architectures can become cumbersome. Scaling the application often requires scaling the entire monolith, even if only a small part of it is under heavy load. Additionally, making changes to one part of the application can have unintended consequences on other parts, leading to increased risk and complexity.
Microservices Architecture
Microservices architecture addresses these challenges by breaking the application down into smaller, loosely coupled services. Each service is responsible for a specific business capability and can be developed, deployed, and scaled independently. However, the transition to microservices also introduces new complexities, particularly in the area of data management. In a monolithic application, data is typically stored in a single relational database. In a microservices architecture, each service may have its own data storage requirements, leading to the need for polyglot persistence.
Checkout this article to understand the differences between monolithic and microservices architecture in detail: Microservices vs. Monoliths: When to Choose Which Architecture
Understanding Polyglot Persistence
Definition
Polyglot persistence is the practice of using multiple database technologies within a single application to store different types of data. The term “polyglot” refers to the use of multiple languages, and in this context, it refers to the use of multiple database “languages” or technologies. The phrase “polyglot persistence” was first used by Scott Leberknight in his blog.
The idea behind polyglot persistence is that different types of data have different storage and retrieval requirements, and no single database technology is optimal for all use cases. By using multiple databases, each chosen for its strengths in handling specific types of data, developers can optimize the performance, scalability, and maintainability of their applications.
Why Polyglot Persistence?
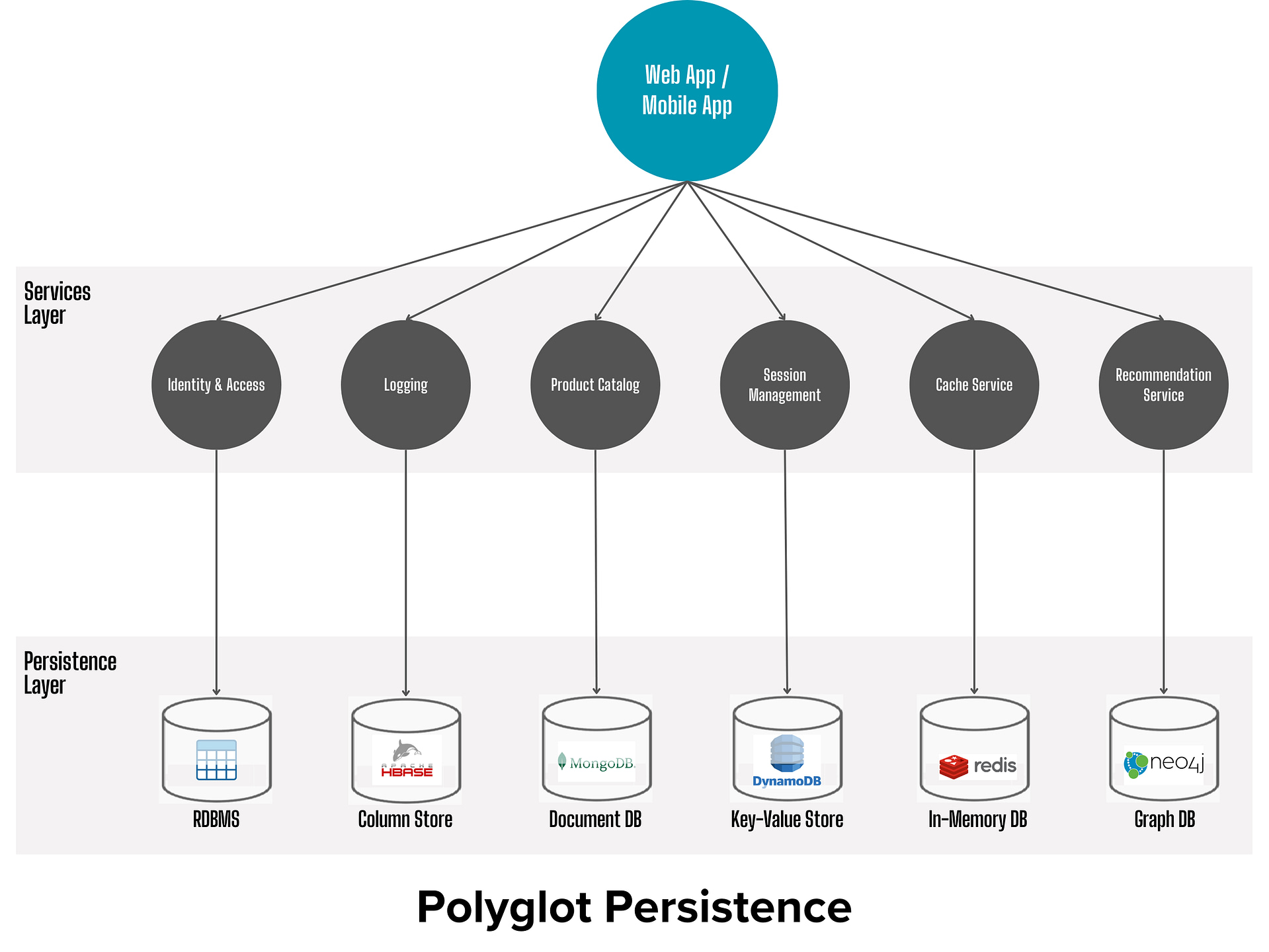
In a microservices architecture, each service is responsible for a specific business capability and may have unique data storage requirements. For example:
- A user authentication service may need to store user credentials and session data, which requires high security and fast read/write access.
- A product catalog service may need to store product information, which requires complex querying and indexing capabilities.
- A recommendation service may need to store user behavior data, which requires high write throughput and the ability to handle large volumes of unstructured data.
Using a single relational database for all these services may not be optimal. Instead, polyglot persistence allows each service to use the database technology that best meets its specific needs.
Advantages
Optimized Performance
Different databases are optimized for different types of data and workloads. By using the right database for each service, you can achieve better performance and scalability. As an example, in-memory databases perform much faster than relational databases for caching use-cases.
Flexibility
Polyglot persistence allows you to choose the best database for each service’s specific requirements, rather than being constrained by a one-size-fits-all solution. For example, document databases like MongoDB allow you add new attributes to products on the fly without requiring an explicit schema change. In a traditional relational database, adding a new attribute would require a schema change to the table which can result in maintenance downtime and application availability during every such change.
Resilience
Using multiple databases can improve the resilience of your application. If one database experiences issues, it may not impact the entire application.
Cost Efficiency
By using specialized databases for specific use cases, you can reduce the cost of over-provisioning a single database to handle all types of data.
Innovation
Polyglot persistence enables you to take advantage of the latest database technologies and innovations, rather than being tied to a single, potentially outdated, database.
Challenges
While polyglot persistence offers many benefits, it also introduces several challenges:
Complexity
Managing multiple databases increases the complexity of your architecture. Each database has its own configuration, maintenance, and monitoring requirements.
Data Consistency
Ensuring data consistency across multiple databases can be challenging, particularly in a distributed system where services may need to communicate and share data.
Operational Overhead
Each database may require different operational practices, tools, and expertise. This can increase the operational overhead and require a more skilled team.
Integration
Integrating multiple databases with your application and ensuring they work together seamlessly can be complex.
Cost
While polyglot persistence can be cost-efficient in some cases, it can also lead to increased costs if not managed properly. Each database may have its own licensing, hosting, and maintenance costs.
Choosing the Right Database for Each Service
One of the key aspects of polyglot persistence is choosing the right database for each service. This decision should be based on the specific data storage and retrieval requirements of the service. Below are some common types of databases and their typical use cases:
| Database Type | Popular Platforms | Use Cases | Examples |
|---|---|---|---|
| Relational Databases | - MySQL - PostgreSQL | - Structured data with well-defined schemas. - Complex queries and transactions. - Data integrity and consistency are critical. | - User authentication service (storing user credentials). - Order management service (storing order and payment information). |
| Document Stores | - MongoDB, - Couchbase | - Semi-structured or unstructured data. - Hierarchical data (e.g., JSON documents). - High read/write throughput. | - Product catalog service (storing product information). - Content management service (storing articles, blogs, etc.). |
| Key-Value Stores | - Redis - DynamoDB | - Simple data models with key-value pairs. - High-speed data access. - Caching and session storage. | - Session management service (storing user sessions). - Caching service (storing frequently accessed data). |
| Column-Family Stores | - Cassandra - HBase | - Large volumes of data with high write throughput. - Distributed data storage. - Time-series data. | - Logging service (storing application logs). - IoT data service (storing sensor data). |
| Graph Databases | - Neo4j - Amazon Neptune | - Data with complex relationships and connections. - Social networks, recommendation engines. - Fraud detection and network analysis. | - Recommendation service (storing user behavior and relationships). - Social network service (storing user connections and interactions). |
| Search Engines | - Elasticsearch - Solr | - Full-text search and complex search queries. - Log and event data analysis. - Real-time search and analytics. | - Search service (providing search functionality for products, articles, etc.). - Log analysis service (analyzing application logs for insights). |
| Time-Series Databases | - InfluxDB - TimescaleDB | - Time-stamped data (e.g., metrics, sensor data). - High write throughput and efficient time-based queries. - Monitoring and analytics. | - Monitoring service (storing and analyzing system metrics). - IoT data service (storing and analyzing sensor data). |
| In-Memory Databases | - Redis - Memcached | - High-speed data access. - Caching and session storage. - Real-time data processing. | - Caching service (storing frequently accessed data). - Real-time analytics service (processing and analyzing data in real-time). |
Implementing Polyglot Persistence in Microservices
Step 1: Identify Data Storage Requirements
The first step in implementing polyglot persistence is to identify the data storage requirements for each service. This involves understanding the type of data each service will handle, the expected workload (read-heavy, write-heavy, or balanced), and any specific performance or scalability requirements.
Step 2: Choose the Right Database for Each Service
Based on the data storage requirements, choose the most appropriate database for each service. Consider factors such as data model, query complexity, performance, scalability, and operational overhead.
Step 3: Design Data Access Layers
Each service should have its own data access layer that abstracts the underlying database. This allows the service to interact with the database without being tightly coupled to it. The data access layer should handle database connections, queries, and transactions, and provide a clean API for the service to use.
Step 4: Implement Data Consistency Strategies
In a polyglot persistence environment, ensuring data consistency across multiple databases can be challenging. Consider using strategies such as:
Eventual Consistency
Eventual consistency means that data may be temporarily inconsistent but will eventually become consistent. Your application must be aware of this and must contain wait and retry logic in its data access layer.
SAGA Pattern
Use SAGA pattern to orchestrate changes across multiple databases and maintain data consistency. SAGA ensures that a transaction is either committed or rolled back across multiple databases without leaving stale and inconsistent data in any of the databases.
Event Sourcing
Store changes to data as a sequence of events, which can be replayed to reconstruct the current state.
Step 5: Monitor and Optimize
Monitoring and optimizing the performance of each database is crucial in a polyglot persistence environment. Use monitoring tools to track database performance, identify bottlenecks, and optimize queries and configurations.
Step 6: Plan for Data Migration and Evolution
As your application evolves, you may need to migrate data between databases or change the database technology used by a service. Plan for data migration and evolution by using techniques such as:
Database Abstraction
Use an abstraction layer to decouple the service from the underlying database, making it easier to switch databases in the future.
Data Versioning
Implement data versioning to handle changes in data schemas and formats.
Backup and Restore
Regularly back up data and test restore procedures to ensure data can be recovered in case of failure.
Best Practices for Polyglot Persistence
Start Simple
Begin with a single database and only introduce additional databases when there is a clear need. Avoid over-complicating your architecture from the start.
Use the Right Tool for the Job
Choose the database that best meets the specific requirements of each service. Avoid forcing a single database to handle all types of data.
Decouple Services and Databases
Ensure that each service is loosely coupled to its database. Use a data access layer to abstract the database and provide a clean API for the service.
Ensure Data Consistency
Implement strategies to ensure data consistency across multiple databases, such as eventual consistency, distributed transactions, or event sourcing.
Monitor and Optimize
Continuously monitor the performance of each database and optimize as needed. Use monitoring tools to track database performance and identify bottlenecks.
Plan for Data Migration
Plan for data migration and evolution by using techniques such as database abstraction, data versioning, and backup and restore procedures.
Invest in Training and Expertise
Ensure your team has the necessary skills and expertise to manage multiple databases. Invest in training and consider hiring specialists if needed.
Document and Communicate
Document your polyglot persistence strategy and communicate it to your team. Ensure everyone understands the rationale behind the chosen databases and how they should be used.
Real-world Examples: Polyglot Persistence in Action
Example 1: E-Commerce Platform
If you are building an e-commerce platform, you can implement polyglot persistence to optimize data storage for different services:
- User Authentication Service: Uses a relational database (PostgreSQL) to store user credentials and session data, ensuring data integrity and security.
- Product Catalog Service: Uses a document store (MongoDB) to store product information, allowing for flexible schema and complex queries.
- Recommendation Service: Uses a graph database (Neo4j) to store user behavior and relationships, enabling personalized recommendations.
- Order Management Service: Uses a relational database (MySQL) to store order and payment information, ensuring transactional consistency.
- Caching Service: Uses an in-memory database (Redis) to store frequently accessed data, improving performance and reducing load on other databases.
Example 2: Social Network
If you are building a social network platform, polyglot persistence can help you handle different types of data:
- User Profile Service: Uses a relational database (PostgreSQL) to store user profiles and relationships, ensuring data integrity and complex queries.
- Activity Feed Service: Uses a column-family store (Cassandra) to store user activity data, enabling high write throughput and scalability.
- Messaging Service: Uses a document store (MongoDB) to store messages and nested replies in conversations, allowing for flexible schema and fast read/write access.
- Search Service: Uses a search engine (Elasticsearch) to provide full-text search functionality for user profiles, posts, and messages.
- Analytics Service: Uses a time-series database (InfluxDB) to store and analyze user activity and engagement metrics.
Conclusion
Polyglot persistence is a powerful approach to data management in a microservices architecture. By using multiple databases, each chosen for its strengths in handling specific types of data, developers can optimize the performance, scalability, and maintainability of their applications.
However, polyglot persistence also introduces new challenges, including increased complexity, data consistency, and operational overhead. To successfully implement polyglot persistence, it is essential to carefully choose the right database for each service, design robust data access layers, implement data consistency strategies, and continuously monitor and optimize database performance.
For database developers transitioning from monolithic to microservices architecture, understanding and embracing polyglot persistence is crucial. By doing so, you can build more flexible, scalable, and resilient applications that are better equipped to meet the demands of modern software development.
References
https://martinfowler.com/bliki/PolyglotPersistence.html
https://www.sleberknight.com/blog/sleberkn/entry/polyglot_persistence


[…] Polyglot Persistence: A Comprehensive Guide for Database Developers Transitioning to Microservices A… Amazon DynamoDB: A Developer’s Comprehensive Primer […]
[…] Polyglot Persistence: A Comprehensive Guide for Database Developers Transitioning to Microservices Architecture, Zugriff am Oktober 26, 2025, https://thedeveloperspace.com/polyglot-persistence/ […]
[…] Polyglot Persistence: A Comprehensive Guide for Database Developers Transitioning to Microservices Architecture, Zugriff am Oktober 26, 2025, https://thedeveloperspace.com/polyglot-persistence/ […]