Read Time14 Minute, 2 Second
Contents
Introduction: The Cloud Has Grown Up
Remember when “going cloud” meant picking AWS and calling it a day? Those days are firmly behind us.
For the better part of a decade, the corporate playbook was simple: migrate everything to a major public cloud provider: AWS, Azure, or GCP, and enjoy the scalability. That era, which we can call Cloud 1.0 and 2.0, was defined by migration and optimization. But in 2026, the rules have changed fundamentally.
Welcome to Cloud 3.0, an era where the cloud isn’t a destination, it’s a strategy. It’s no longer about where your server is. It’s about how your data is governed, who controls it, and how quickly it can be accessed from anywhere in the world.
As a developer, understanding Cloud 3.0 isn’t optional anymore. It shapes the architectures you’ll design, the tools you’ll use, and the decisions you’ll make about where workloads live. This guide breaks it all down.
What Cloud 3.0 Actually Means (And What It Doesn’t)
Before we go further, let’s clear something up, because “Cloud 3.0” is one of those terms that sounds like marketing until you understand the shift it’s describing.
Think about how electricity works. In the early 1900s, every factory built its own power generator on-site. It was expensive, required dedicated engineers to maintain, and the power never left the building. Then the public electricity grid arrived, factories could plug in, pay for what they used, and forget about generators entirely. That’s what Cloud 1.0 felt like for computing: you could finally stop managing physical servers and just “plug in” to AWS or Azure.
But here’s where the analogy gets interesting. Today, no serious business runs entirely on the public grid without thought. Hospitals have backup generators. Data centres have uninterruptible power supplies. Nuclear plants run their own isolated power systems entirely. And large manufacturers negotiate custom energy contracts across multiple suppliers to control cost and avoid outages. Nobody calls this “leaving the grid”, it’s just mature, deliberate energy strategy.
That’s exactly what Cloud 3.0 is: mature, deliberate cloud strategy. It’s not a rejection of public cloud, and it’s not a return to on-premises servers. It’s the recognition that different workloads, like different industrial processes, have different requirements, and that a single cloud provider can’t optimally serve all of them.
Here’s another analogy that might hit closer to home. Think about how we moved from monolithic applications to microservices. Nobody threw away their entire codebase. Instead, teams started asking: which parts of this system have unique requirements that a single architecture can’t serve well? The result was a deliberate decomposition, not chaos, but intentional separation based on the specific needs of each service.
Cloud 3.0 applies the same thinking to infrastructure. Instead of decomposing your application into services, you’re decomposing your infrastructure into environments, each one chosen for what it does best:
- Public cloud for elasticity, global reach, and GPU-heavy AI training
- Private or on-premises infrastructure for predictable, high-volume compute that’s cheaper to own
- Sovereign cloud for regulated data that legally cannot cross borders
- Edge locations for workloads that need to process data close to the source
The misconception to avoid is thinking of Cloud 3.0 as “complexity for its own sake.” Teams that bolt multiple clouds together without strategy end up with higher bills, inconsistent security, and operational chaos. Cloud 3.0 done right means fewer decisions made by default, and more decisions made deliberately, with a clear reason why each workload lives where it does.
What Is Cloud 3.0?
Cloud 3.0 represents the third distinct generation of cloud computing:
- Cloud 1.0 (2006–2014): The IaaS era. AWS EC2 launched in 2006, and the world learned you could rent compute instead of buying servers. The goal was lift-and-shift, moving legacy workloads to virtual machines.
- Cloud 2.0 (2014–2022): The PaaS/SaaS era. Kubernetes, microservices, cloud-native development, and big data pipelines took over. Speed and developer productivity were the priorities.
- Cloud 3.0 (2022–present): The sovereign, distributed, AI-ready era. The focus has shifted to resilience, compliance, data governance, and intelligent workload placement across hybrid and multi-cloud environments.
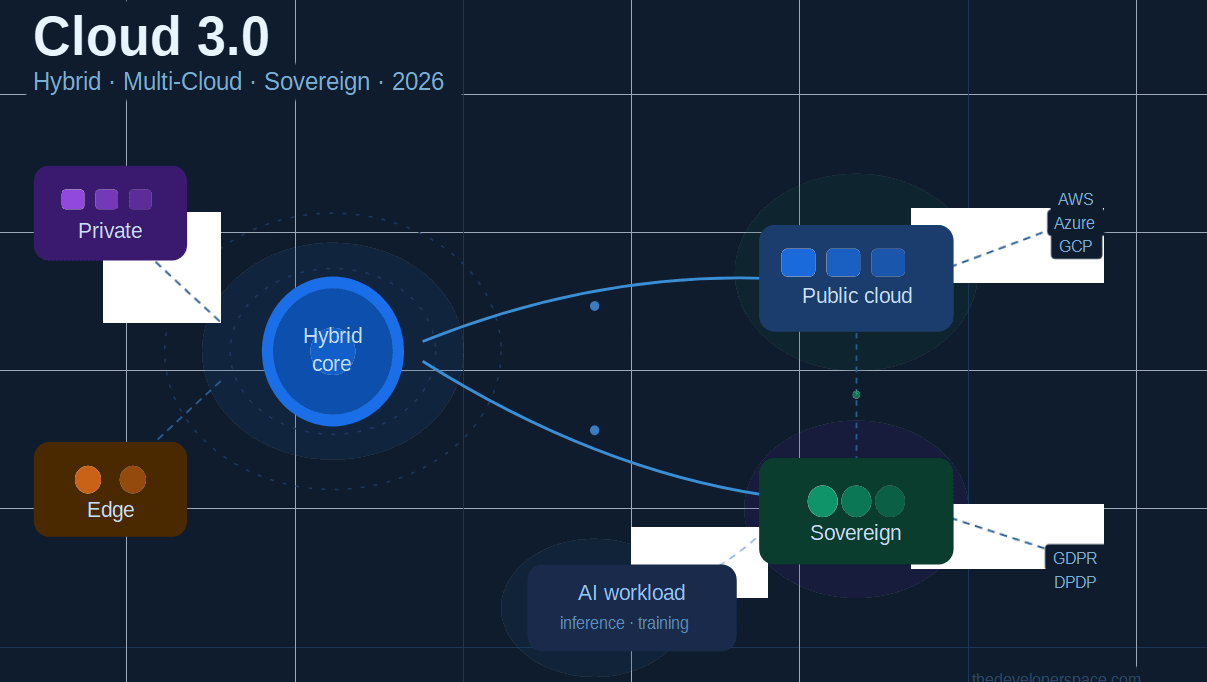
In short: Cloud 3.0 is a diversified cloud ecosystem combining hybrid, multi-cloud, and sovereign architectures to simultaneously meet performance, compliance, and AI scalability demands. It’s not an IT refresh. It’s a new operating model.
Part 1: Hybrid Cloud – The Best of Both Worlds
What is it?
A hybrid cloud combines private infrastructure (on-premises servers or colocation data centres) with public cloud platforms, connected through secure networking and unified management tools. Workloads move fluidly between environments based on requirements.
Why developers care
Not every workload belongs in a public cloud. A hospital’s patient records, a bank’s transaction logs, a defense contractor’s proprietary algorithms, these need to live in controlled environments. But the same organizations still need public cloud elasticity for web-facing applications, burst capacity, and AI experimentation.
Hybrid cloud solves this by letting teams make deliberate workload placement decisions:
- Sensitive data and regulated workloads → private cloud or on-prem
- High-scale, burst, or public-facing workloads → public cloud
- AI training (needs massive GPU power) → public cloud; AI inference (uses proprietary user data) → private or sovereign cloud
Key tools to know
- AWS Outposts brings AWS infrastructure physically into your data center
- Azure Arc extends Azure management across on-prem, multi-cloud, and edge environments
- Google Anthos runs Kubernetes clusters anywhere, managed from a single control plane
- HashiCorp Terraform infrastructure-as-code for provisioning across environments consistently
Pros and Cons at a glance
| Pros | Cons |
|---|---|
| Fine-grained control over sensitive data | Higher operational complexity |
| Regulatory compliance without sacrificing agility | Requires skilled DevOps/platform engineering |
| Cost optimization: run baseline on-prem, burst on cloud | Networking between environments can be tricky |
| Reduces vendor lock-in risk | Security surface area increases |
Part 2: Multi-Cloud Strategy – No More Cloud Monogamy
What is it?
Multi-cloud means using two or more public cloud providers simultaneously, for example, running your ML workloads on GCP (for its TPUs and Vertex AI), your enterprise apps on Azure (for deep Microsoft integrations), and your media delivery on AWS (for CloudFront). According to Flexera’s 2026 State of the Cloud Report, 83% of large enterprises now use multi-cloud strategies, and that number keeps climbing.
Why developers care
No single cloud provider excels at everything. Multi-cloud lets teams pick the best service for each job. It also guards against outages, avoids pricing lock-in, and satisfies procurement teams who don’t want a single point of failure.
The real challenges (and how to handle them)
1. Vendor lock-in at the service layer The biggest multi-cloud trap is using proprietary services (like AWS DynamoDB or Azure Cosmos DB) so deeply that migrating becomes impractical. The fix: lean on open standards. Use OCI-compatible container images, standard SQL databases, and Kubernetes for orchestration wherever possible. Portability should be a design principle, not an afterthought.
2. Identity and access management across clouds Each cloud has its own IAM model. Tools like HashiCorp Vault for secrets management and SPIFFE/SPIRE for workload identity help unify access control across providers.
3. Observability Distributed tracing and monitoring across clouds is hard. Adopt tools like OpenTelemetry (vendor-neutral telemetry), Grafana, or Datadog early, before your architecture sprawls.
4. Networking Inter-cloud data transfer costs money. Design data flows to minimize cross-cloud egress. Use a cloud-agnostic service mesh like Istio or Linkerd to manage east-west traffic consistently.
The “Big Three + Sovereign” model
Multi-cloud is evolving beyond AWS, Azure, and GCP. Regional and sovereign cloud providers, such as Germany’s Gaia-X, France’s OVHcloud, and various national government clouds, are becoming legitimate options for enterprises with strict data residency requirements. A mature multi-cloud strategy in 2026 might combine a hyperscaler for scale, a sovereign provider for compliance, and edge locations for latency.
Part 3: Sovereign Cloud – Data as a National Resource
What is it?
Sovereign cloud is cloud infrastructure that is physically located within a specific country or region and operated by local entities, ensuring data never leaves a defined legal jurisdiction and is subject to local laws rather than foreign ones.
Multinational companies can no longer simply store German or Brazilian customer data in a US-based data center. Regional data acts have changed the game, and governments increasingly treat data the way they treat natural resources: as something that must be protected and governed within borders.
Why developers care
If you’re building applications for global markets, especially in finance, healthcare, government, or defense, your architecture must now account for where data lives at rest and in transit. This is not just a compliance team problem. It’s a database schema problem, an API design problem, and a deployment topology problem.
The Three-Tier Cloud 3.0 Architecture
A practical way to design for sovereignty is the Three-Tier model:
- The Private Core: Your most sensitive intellectual property and proprietary datasets. You maintain 100% control here, with no external cloud involvement.
- The Sovereign Layer: Customer data and regulated workloads that must remain within specific legal jurisdictions. Hosted on sovereign or regional cloud infrastructure.
- The Public Utility: Non-sensitive, high-scale workloads like CDN, public APIs, and marketing sites. Hosted on public hyperscalers for maximum elasticity and global reach.
What to watch in 2026
Gartner identifies Geopatriation as a top strategic tech trend this year, the deliberate shift of workloads to sovereign or regional cloud providers to mitigate geopolitical risk. As a developer, expect to see data residency requirements baked into infrastructure-as-code templates and CI/CD pipelines as a standard compliance gate.
Part 4: AI + Cloud 3.0 – The Accelerator
AI is simultaneously the biggest driver of Cloud 3.0 and the biggest beneficiary of it.
Large model training requires the kind of GPU clusters that only hyperscalers can provide at scale. But inference, actually running those models against real user data, often involves sensitive information that can’t leave a private or sovereign environment.
This creates a natural hybrid pattern:
- Train on public cloud (AWS, Azure, or GCP with A100/H100 clusters)
- Fine-tune on sovereign or private infrastructure (with your proprietary data)
- Deploy inference endpoints in the environment closest to users and compliant with local law
Cloud 3.0 architectures make this separation clean, repeatable, and auditable. As AI workloads grow more complex, the organizations that have built flexible hybrid and multi-cloud foundations will have a significant competitive advantage.
Part 5: Key Developer Skills to Learn
Cloud 3.0 demands a broader skill set than traditional cloud-native development. Here’s where to focus your energy:
Infrastructure & Orchestration
- Kubernetes (multi-cluster management with tools like Cluster API or Rancher)
- Terraform / OpenTofu for multi-cloud IaC
- Helm for Kubernetes application packaging
Networking & Security
- Service mesh fundamentals (Istio, Linkerd, Cilium)
- Zero-trust networking principles
- Cloud-agnostic secrets management (Vault, AWS Secrets Manager, Azure Key Vault, and abstracting over them)
Observability
- OpenTelemetry for instrumentation
- Distributed tracing across cloud boundaries
- Cost observability: understanding and controlling inter-cloud data transfer costs
Compliance & Governance
- Data residency basics, know what GDPR, India’s DPDP Act, and similar frameworks require from an infrastructure standpoint
- Policy-as-code with tools like Open Policy Agent (OPA)
AI Infrastructure
- Understanding GPU instance types across providers
- Model serving frameworks (TorchServe, Triton, vLLM)
- Data pipeline design for hybrid environments (Kafka, Apache Flink, Airflow)
Conclusion
Cloud 3.0 isn’t a buzzword, it’s the architectural reality of 2026. The old “all-in on one hyperscaler” approach is giving way to a more nuanced, intentional model where developers think carefully about where each workload belongs, who governs the data, and how systems remain resilient across environments.
The good news: you don’t have to overhaul everything at once. The best advice is to start with one workload, move it to a secondary provider or private environment, and learn the operational differences. Build portability into your architecture from day one using open standards, and let compliance requirements guide your sovereign layer decisions.
The developers who understand this shift will be the architects of the next decade of digital infrastructure. Start learning now.
Related Articles
Further Reading
- Gartner Top Strategic Technology Trends 2026
- Capgemini TechnoVision 2026 Report
- Flexera 2026 State of the Cloud Report
- OpenTelemetry Documentation
- Open Policy Agent (OPA)
- HashiCorp Vault
External Links
Found this useful? Share it with your team and follow The Developer Space for weekly deep dives into the technologies shaping modern development.