
Read Time10 Minute, 8 Second
As you advance your SQL skills, you’ll find situations where writing a single flat query isn’t enough. That’s where subqueries come in. A subquery, or nested query, is a query within another SQL query. It allows you to break complex problems into smaller, manageable parts and can make your queries more powerful and expressive.
In this article, we’ll walk through the fundamentals of subqueries, explain different types, and demonstrate how to use them effectively with examples.
Contents
Articles in the Series
Before reading this article, I recommend that you read the previous articles in this series to understand the basics and to set up the Sample database that we’ll be using for the examples in the article.
![]() SQL for Beginners: Learn the Basics with Examples
SQL for Beginners: Learn the Basics with Examples
![]() SQL for Beginners – Part 2: SELECT Commands with Examples
SQL for Beginners – Part 2: SELECT Commands with Examples
![]() SQL for Beginners – Part 3: JOINS
SQL for Beginners – Part 3: JOINS
![]() SQL for Beginners – Part 4: Mastering Subqueries
SQL for Beginners – Part 4: Mastering Subqueries
Setting up the Sample Database
The examples in these article series were created using PostgreSQL (Database) and DbStudio (IDE). However, you can try out these examples in any Relational Database. You may have to tweak the syntax to make it work with your target database platform.
We created the Users and Orders tables in the previous articles (scroll down to the bottom). We’ll reuse these table for code examples in this article.
All code samples in this article can be accessed here: https://github.com/The-Developer-Space/CodeSamples/blob/main/SQL_for_Beginners
What Is a Subquery?
A subquery, also known as a nested query, is a query that is written inside another SQL query and is enclosed within parentheses. It is used to retrieve data that will be used by the main (outer) query to further refine results. Subqueries can be placed in various parts of a SQL statement, such as the WHERE, FROM, or SELECT clauses, allowing you to break down complex logic into smaller, more manageable components. By enabling one query to depend on the result of another, subqueries make SQL more powerful and expressive, especially when filtering, aggregating, or computing values based on related data.
A subquery can return a single value, or a set of values, a single row or multiple rows. The outer query typically determines what a subquery should return.
Subquery Syntax:
SELECT column_name FROM table_name WHERE column_name OPERATOR ( SELECT column_name FROM another_table );
Subquery in the WHERE Clause
A Subquery in the WHERE clause filters results based on the outcome of another query.
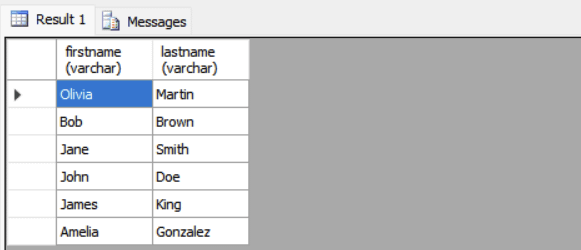
Example: Find users who have placed at least one order.
SELECT FirstName, LastName FROM Users WHERE UserID IN (SELECT UserID FROM Orders);
The subquery retrieves all UserID values from the Orders table. The outer query then selects the names from Users where the UserID exists in the result set of the subquery.
Subquery in the SELECT Clause
You can use subqueries to calculate a value that appears as a column in the result.
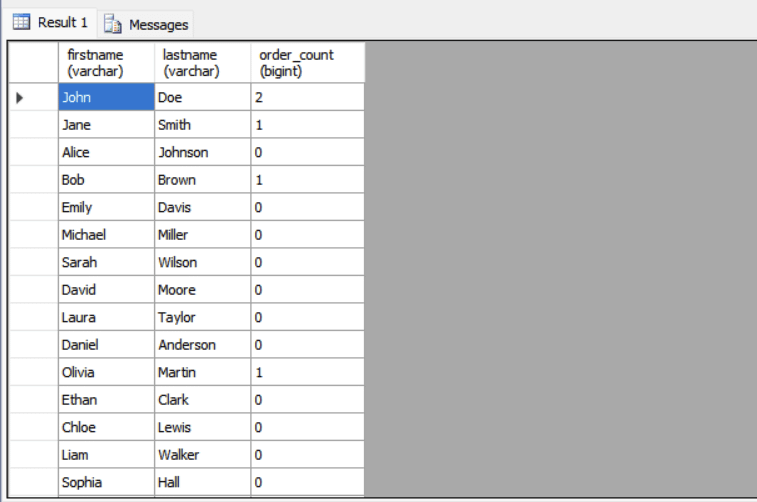
Example: Get each user’s name and the number of orders they have placed.
SELECT FirstName, LastName,
(SELECT COUNT(*) FROM Orders WHERE Orders.UserID = Users.UserID) AS order_count
FROM Users;For each user in the Users table, the subquery counts how many orders exist in the Orders table that match the user’s ID.
Subquery in the FROM Clause
Sometimes, you can treat a subquery like a temporary table and select from it.
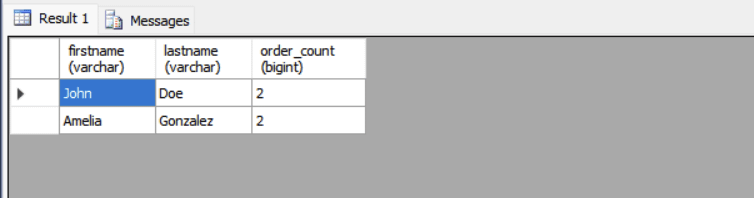
Example: List users with more than one orders.
SELECT FirstName, LastName, order_count FROM (
SELECT Users.FirstName, Users.LastName, COUNT(Orders.OrderID) AS order_count
FROM Users
JOIN Orders ON Users.UserID = Orders.UserID
GROUP BY Users.FirstName, Users.LastName
) AS UserOrders
WHERE order_count > 1;The inner query generates a result set of each user’s name and their order count. The outer query filters this result to include only users with more than one orders.
Correlated Subquery vs Non-Correlated Subquery
Understanding the difference between correlated and non-correlated subqueries is essential for writing efficient and effective SQL queries.
Non-Correlated Subquery
This type of subquery runs independently of the outer query. It is evaluated once, and its result is passed to the outer query. It doesn’t rely on data from the outer query and usually provides better performance. These are often used in WHERE, IN, or FROM clauses where the subquery returns a static set of values.
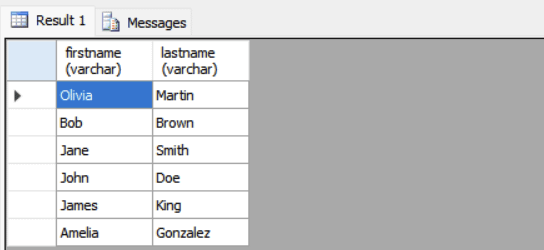
Example: Find users who have placed at least one order:
SELECT FirstName, LastName FROM Users WHERE UserID IN (SELECT UserID FROM Orders);
The subquery retrieves all UserID from Orders. The outer query then returns names from Users where UserID is not in the list. The subquery is executed only once.
Correlated Subquery
Unlike non-correlated subqueries, correlated subqueries reference columns from the outer query. This means they are executed once for every row considered by the outer query. They are useful when each row of the outer query needs to be evaluated against a dynamic condition. However, they can be significantly slower due to repeated execution.
Example:
SELECT FirstName, LastName FROM Users U WHERE EXISTS ( SELECT 1 FROM Orders O WHERE O.UserID = U.UserID );
The inner query checks if there exists at least one order for each user. It references Users.UserID from the outer query, so it must be executed for each user row. You’ll notice that the results are same in this case.
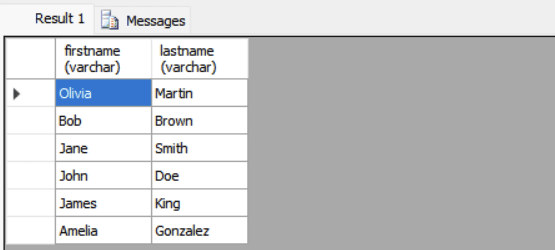
Note that almost all correlated subqueries can be rewritten using JOINs. A JOIN typically provides better performance compared to an equivalent correlated subquery.
Subquery with EXISTS
The EXISTS keyword is used to check for the existence of rows returned by a subquery.
Example:
SELECT FirstName, LastName FROM Users U WHERE EXISTS ( SELECT 1 FROM Orders O WHERE O.UserID = U.UserID );
If the subquery returns any rows, the user is included in the result. This is useful for filtering users who have related data in another table.
Subquery with NOT IN or NOT EXISTS
You can also use subqueries to exclude certain records.
Example: Find users who haven’t placed any orders:
SELECT FirstName, LastName FROM Users WHERE UserID NOT IN (SELECT UserID FROM Orders);
Or using NOT EXISTS:
SELECT FirstName, LastName FROM Users U WHERE NOT EXISTS ( SELECT 1 FROM Orders O WHERE O.UserID = U.UserID );
Both queries return users who have not placed any orders. The NOT EXISTS version is often preferred for handling NULL values.
Subquery vs Join
While both subqueries and joins can be used to combine data from multiple tables, they work differently and have different performance characteristics.
JOINs
Joins combine data from two or more tables based on related columns. They are often more readable and can be more efficient for large datasets, especially when multiple rows need to be returned from both tables.
Example:
SELECT Users.FirstName, Users.LastName, COUNT(Orders.OrderID) AS order_count FROM Users LEFT JOIN Orders ON Users.UserID = Orders.UserID GROUP BY Users.FirstName, Users.LastName;
Subquery
Subqueries return a single value or a set of values to be used in the outer query. They are useful when you need to compute something before the main query executes, especially for filtering or scalar results.
Example:
SELECT FirstName, LastName
(SELECT COUNT(*) FROM Orders WHERE Orders.UserID = Users.UserID) AS order_count
FROM Users;Key difference: The JOIN aggregates data by combining rows from both tables, while the subquery approach performs a lookup for each row. Use JOINs for combining multiple rows across tables and subqueries for scalar lookups or filtering.
Advanced Subquery Examples
Users With Above-Average Orders
To find out all users who have made orders that is above the average of all user orders. Use the following query:
SELECT FirstName, LastName
FROM Users U
WHERE
(SELECT COUNT(*) FROM Orders O WHERE O.UserID = O.UserID)
>
(SELECT AVG(order_count) FROM (
SELECT UserID, COUNT(*) AS order_count
FROM Orders
GROUP BY UserID)
AS UserOrderCounts
);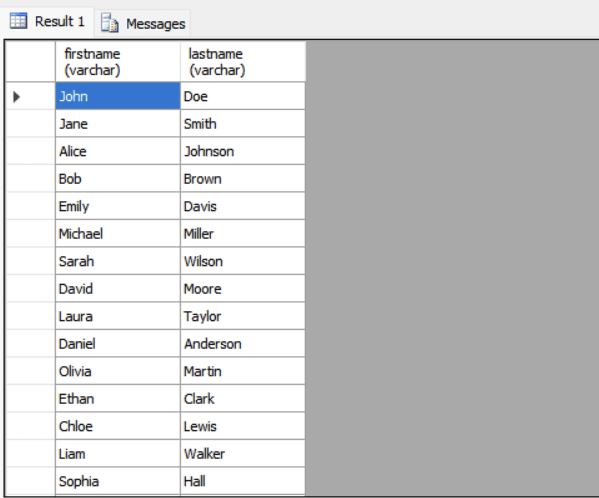
- The inner subquery
SELECT AVG(order_count)...calculates the average number of orders placed per user. - The correlated subquery
SELECT COUNT(*) FROM Orders O WHERE O.UserID = U.UserIDcounts the orders for each user. - The outer query filters and returns only those users whose individual order count is greater than the average.
This example demonstrates how subqueries can be combined and layered for advanced filtering and insights based on aggregated data.
Subquery Best Practices
- Use correlated subqueries only when necessary; they can be slow with large datasets.
- For better performance, consider converting subqueries to
JOINs or using CTEs (Common Table Expressions). - Always test subqueries independently to ensure they return expected results.
Conclusion
Subqueries are a powerful tool in SQL that allow you to solve complex queries by nesting logic. Whether you’re filtering data, computing aggregates, or checking existence, subqueries open up new ways to manipulate and retrieve data effectively. Practice writing different types of subqueries to deepen your understanding and make your SQL skills truly versatile.
Stay tuned for the next part, where we’ll explore a few more features to further level up your SQL journey!

[…] SQL for Beginners – Part 4: Mastering Subqueries […]
[…] SQL for Beginners – Part 4: Mastering Subqueries […]
[…] SQL for Beginners – Part 4: Mastering Subqueries […]
[…] SQL for Beginners – Part 4: Mastering Subqueries […]
[…] SQL for Beginners – Part 4: Mastering Subqueries […]