Read Time15 Minute, 24 Second
Generative AI, one of the most revolutionary advancements in artificial intelligence, enables machines to generate text, images, and even code based on input data. AWS (Amazon Web Services) has become a crucial platform for developers looking to leverage Generative AI at scale, providing cutting-edge tools, infrastructure, and pre-built models. This article will walk through Amazon Bedrock for building and deploying Generative AI solutions, providing valuable insights and code examples for developers looking to dive into this powerful technology.
Contents
Amazon Bedrock
Amazon Bedrock is a fully managed service that provides access to a wide range of foundation models from different AI providers. Bedrock allows you to build and scale generative AI applications without managing any underlying infrastructure.
Before proceeding further, I recommend that you read my previous article that gives an overview of Generative AI on AWS. Generative AI on AWS: 2025 Guide to Bedrock, Foundation Models and SageMaker. To understand Generative AI platforms offered by different cloud providers, head on to Comparison of Generative AI Solutions: AWS vs Azure vs Google Cloud (2024 Guide)
Bedrock SDK
AWS provides two core services for Bedrock:
Bedrock describes the API operations for creating, managing, fine-turning, and evaluating Amazon Bedrock models.
BedrockRuntime describes the API operations for running inference using Amazon Bedrock models.
The code examples in this article are provided in Python and uses the AWS SDK for Python (Boto3) to access AWS resources. They can be executed inside Lambda functions or as standalone programs. Make sure you set up IAM permissions for Lambda functions and other authentication methods if you decide to run them as standalone programs.
You can also use these SDKs to access Amazon Bedrock.
| Platform | Bedrock | Bedrock Runtime |
| C++ | Bedrock | BedrockRuntime |
| Go | Bedrock | BedrockRuntime |
| Java | Bedrock | BedrockRuntime |
| JavaScript | Bedrock | BedrockRuntime |
| Kotlin | Bedrock | BedrockRuntime |
| .NET | Bedrock | BedrockRuntime |
| PHP | Bedrock | BedrockRuntime |
| Ruby | Bedrock | BedrockRuntime |
| Rust | Bedrock | BedrockRuntime |
| SAP ABAP | Bedrock | BedrockRuntime |
| Swift | Bedrock | BedrockRuntime |
Playground
Before accessing the models through API, use the Playground to make sure you are able to access the models from the console. Sometimes, model access issues and service quota limits.
From the Bedrock console, click Chat/text under the Playground menu section. Click on the Select model button and select the required model from the popup screen.
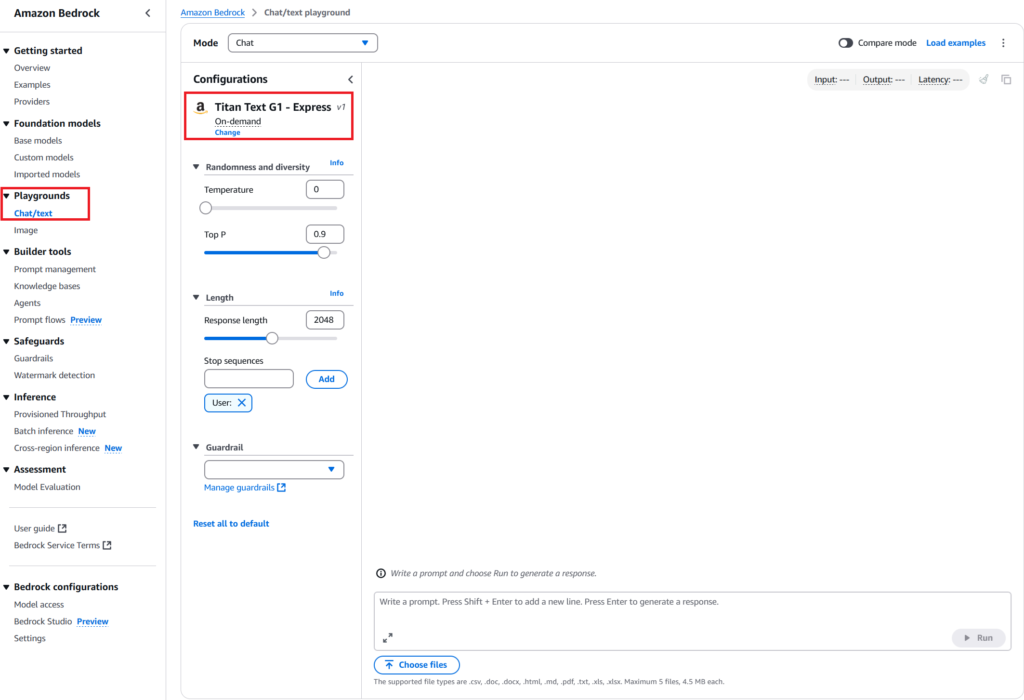
If you are able to use the model and execute your prompts from the Playground, you are good to start writing code.
Guardrails
Guardrails allow you to build safeguards around your generative AI applications to ensure that the responses are safe and compliant. It is used to build responsible AI apps. For example, if you’re building a chatbot, you can use guardrails to filter the responses and remove toxic words, obscene phrases, and topics related to certain blocked categories. Guardrails can be created from the console or through code. When calling the InvokeModel API, you can specify the guardrail to be used to filter the response.
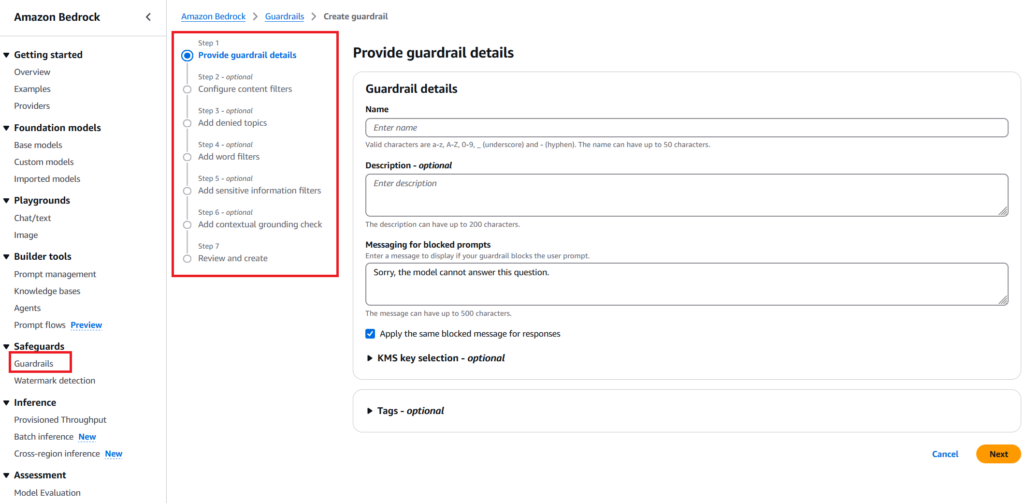
Prerequisites
IAM Permissions
The following IAM policies are required to execute the code samples. If you’re executing the code from Lambda functions, add these policies to the Lambda execution role. If you executing the code locally, add these policies to the User to which the API keys are attached.
– AmazonBedrockFullAccess
– AmazonSageMakerFullAccess
Model Access
The first step toward accessing Bedrock models is to make sure that access to the required models in granted. In the AWS console, go to Bedrock service and on the menu bar, click Model access under Bedrock configurations section.


You can Enable all models at once or enable Specific models that you’re interested in. Please note that accessing models come at a cost and some models are very expensive. Please enable models with caution.
Service Quotas
Service quotas control various parameters like how many invocations you can make per minute, the number of tokens that can be passed per minute, etc.
From Service quota console, click AWS Services and choose Bedrock. Search for ‘InvokeModel‘ and make sure you have enough applied quota to invoke the models.
If you exceed your quotas, you may end up receiving a message like this in your Playground console and the same error message in code.

For more information on Bedrock-specific service quotas, check out this article.
Authentication
There are different ways to configure AWS authentication while using boto3 library locally. A list of such methods can be found here. The examples use the direct method of authenticating with an Access Key and a Secret Key. The session object is used in all code samples to create the boto3 clients.
import boto3
session = boto3.Session(
aws_access_key_id='', #Specify the Access key
aws_secret_access_key='', #Specifu the Secret key
)Prompt Engineering
Before moving ahead with using generative AI, you must understand what a prompt is and what prompt engineering is.
Prompt
A prompt is an input provided to an AI model that guides it to produce a specific output. In the context of generative AI, a prompt usually consists of text, a question, a statement, or a set of instructions that directs the model on what kind of response to generate. For example, a prompt could be as simple as “Write a story about a lost cat” or as detailed as “Generate a marketing tagline for an eco-friendly water bottle.” The quality and structure of the prompt greatly impact the relevance and quality of the model’s response, making it a key element in prompt engineering.
Prompt Engineering
Prompt engineering is the practice of designing and refining prompts to optimize the output of generative AI models. By carefully crafting instructions, context, or constraints within a prompt, developers can guide models to produce more accurate, relevant, or creative responses. Effective prompt engineering is crucial for achieving desired results across various applications, from text generation and image synthesis to data embeddings. This technique allows developers to maximize model performance without altering the model’s underlying architecture.
Bedrock APIs
ListFoundationModels
Bedrock’s ListFoundationModels API lists all foundation models that are available and enabled in your AWS account in the specified region.
import boto3
import json
bedrock = session.client(
service_name='bedrock',
region_name='us-east-1'
)
models = bedrock.list_foundation_models()
for model in models['modelSummaries']:
print(f"Model Name:{model['modelName']}, Id:{model['modelId']}, Provider:{model['providerName']}")This command lists all the foundation models available. The output will be something similar to this and may vary depending on what models are enabled in your account and in the specified region.
Titan Text Large Titan Image Generator G1 Titan Text Embeddings v2 Titan Text G1 - Lite Titan Text G1 - Express Titan Embeddings G1 - Text Titan Text Embeddings V2 Titan Multimodal Embeddings G1 Jurassic-2 Mid Jurassic-2 Ultra Jamba-Instruct Jamba 1.5 Large Jamba 1.5 Mini Claude Instant Claude 3 Sonnet Claude 3 Haiku Claude 3 Opus Claude 3 Opus Command Command R Command R+ Command Light ...............
ListCustomModels
To list all custom models, use the ListCustomModels API.
import boto3
import json
bedrock = session.client(
service_name='bedrock',
region_name='us-east-1'
)
models = bedrock.list_custom_models()
for model in models['modelSummaries']:
print(f"Model Name:{model['modelName']}, Created Time:{model['creationTime']}, Customization Type:{model['customizationType']}")Bedrock Runtime APIs
InvokeModel method
The InvokeModel method invokes the selected Amazon Bedrock model to perform inference based on the prompt and parameters specified in the request body. Model inference can be used to generate text, create images, or produce embeddings.
Request Syntax
response = client.invoke_model(
body=b'bytes'|file,
contentType='string',
accept='string',
modelId='string',
trace='ENABLED'|'DISABLED',
guardrailIdentifier='string',
guardrailVersion='string'
)Response Syntax
{
'body': StreamingBody(),
'contentType': 'string'
}Note that the body parameter that contains the inference request parameters to be sent to the model. Similarly, the response also has a body field that contains the response from the model. The inference request parameters and response fields varies for each model. Check out Inference request parameters and response fields for foundation models for information about each model.
Amazon Titan Models
For example, the Amazon Titan Text models have the following request parameters and response fields. Click on the link above to check the detailed documentation for other models.
Request Syntax
{
"inputText": string,
"textGenerationConfig": {
"temperature": float,
"topP": float,
"maxTokenCount": int,
"stopSequences": [string]
}
}Response Syntax (InvokeModel)
{
"inputTextTokenCount": int,
"results": [{
"tokenCount": int,
"outputText": "\n<response>\n",
"completionReason": "string"
}]
}Response Syntax (InvokeModelWithResponseStream)
{
"chunk": {
"bytes": b'{
"index": int,
"inputTextTokenCount": int,
"totalOutputTextTokenCount": int,
"outputText": "<response-chunk>",
"completionReason": "string"
}'
}
}Use Cases
The examples here use the Amazon Titan models. You can also try out other foundation models from various providers that Bedrock supports. Be warned that using Bedrock APIs has cost implications and make sure you understand and have a control over the costs.
To programmatically access models, you must know the exact model IDs. List of Models IDs can be found here: Amazon Bedrock model IDs
Not all models are available in all regions. To check if a model is available in a region, refer to Model support by AWS Region
Text Generation
With Amazon Bedrock, you can start by accessing the API to interact with various foundation models. For this example, let’s use Bedrock to generate text using Amazon Titan.
import boto3
import json
brt = session.client(service_name='bedrock-runtime', region_name='us-east-1')
prompt = "What is the capital of Hungary?"
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":128,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})
response = brt.invoke_model(
body=body,
modelId="amazon.titan-text-express-v1",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
print(outputText)You should see a response similar to this:
The capital of Hungary is Budapest. The city is divided by the River Danube into two halves: Buda and Pest. Budapest is one of the most beautiful cities in Europe, with many historic buildings, museums, and thermal baths. The city is also known for its vibrant nightlife and excellent cuisine.
Conversational AI and Chatbots
Building chatbots is one of the most common use cases for generative AI. Amazon Bedrock makes it easy to build chatbots by providing a unified API to access different models. Building predictive text solutions using generative AI requires a fair amount of familiarity and experience with prompt engineering. You may have to play around with different input prompts to elicit the right response. You may also have to use different models for different use cases within a single conversational session to improve accuracy and speed. If the use case requires fetching data from backend systems and including these information in the responses, you may consider using Retrieval-Augmented Generation (RAG).
As the response from the model is shared with an end user directly, it is a good use case to implement guardrails. Refer to the guardrails section above to check how to create and configure a guardrail. Once created, you can specify the guardrail identifier and version in the InvokeModel API call as described in this example.
import boto3
import json
chat_session_text = input_param #provide the realtime chat session content here
brt = session.client(service_name='bedrock-runtime', region_name='us-east-1')
prompt = f"Assume that you are a contact center agent. Predict the most appropriate response to the following chat session?: {chat_session_text}"
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":128,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})
response = brt.invoke_model(
body=body,
modelId="amazon.titan-text-express-v1",
accept="application/json",
contentType="application/json",
guardrailIdentifier='',
guardrailVersion=''
)
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
print(outputText)The response depends on the chat session transcript that is passed on to the model. You will have to tweak the prompt with your prompt engineering skills to get the desired result.
Image Generation
The Amazon Titan Image Generator G1 models provide capabilities to generate images from text inputs or take existing images as inputs and modify them.
import boto3
import json
brt = session.client(service_name='bedrock-runtime', region_name='us-east-1')
prompt = "A cat wearing a cap and sitting on a mountain."
body = json.dumps({
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": prompt
},
"imageGenerationConfig": {
"numberOfImages": 1,
"height": 1024,
"width": 1024,
"cfgScale": 8.0,
"seed": 0
}
})
response = brt.invoke_model(
body=body,
modelId="amazon.titan-image-generator-v2:0",
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
base64_image = response_body.get("images")[0]
base64_bytes = base64_image.encode('ascii')
image_bytes = base64.b64decode(base64_bytes)
error_message = response_body.get("error")
if error_message is not None:
print(f"Image generation error: {error_message}")
else:
with open("generated_image.png", "wb") as image_file:
image_file.write(image_bytes)Conclusion
Amazon Bedrock simplifies the development and deployment of generative AI applications, making it an ideal choice for developers seeking to harness the power of Foundation Models. With Bedrock, you can focus on building and enhancing your generative AI solutions without the hassle of infrastructure management. Whether you’re creating a chatbot, a content generation tool, or a unique visual application, Amazon Bedrock provides the tools and scalability needed to bring your ideas to life on AWS.